找到
1
篇与
爬虫
相关的结果
-
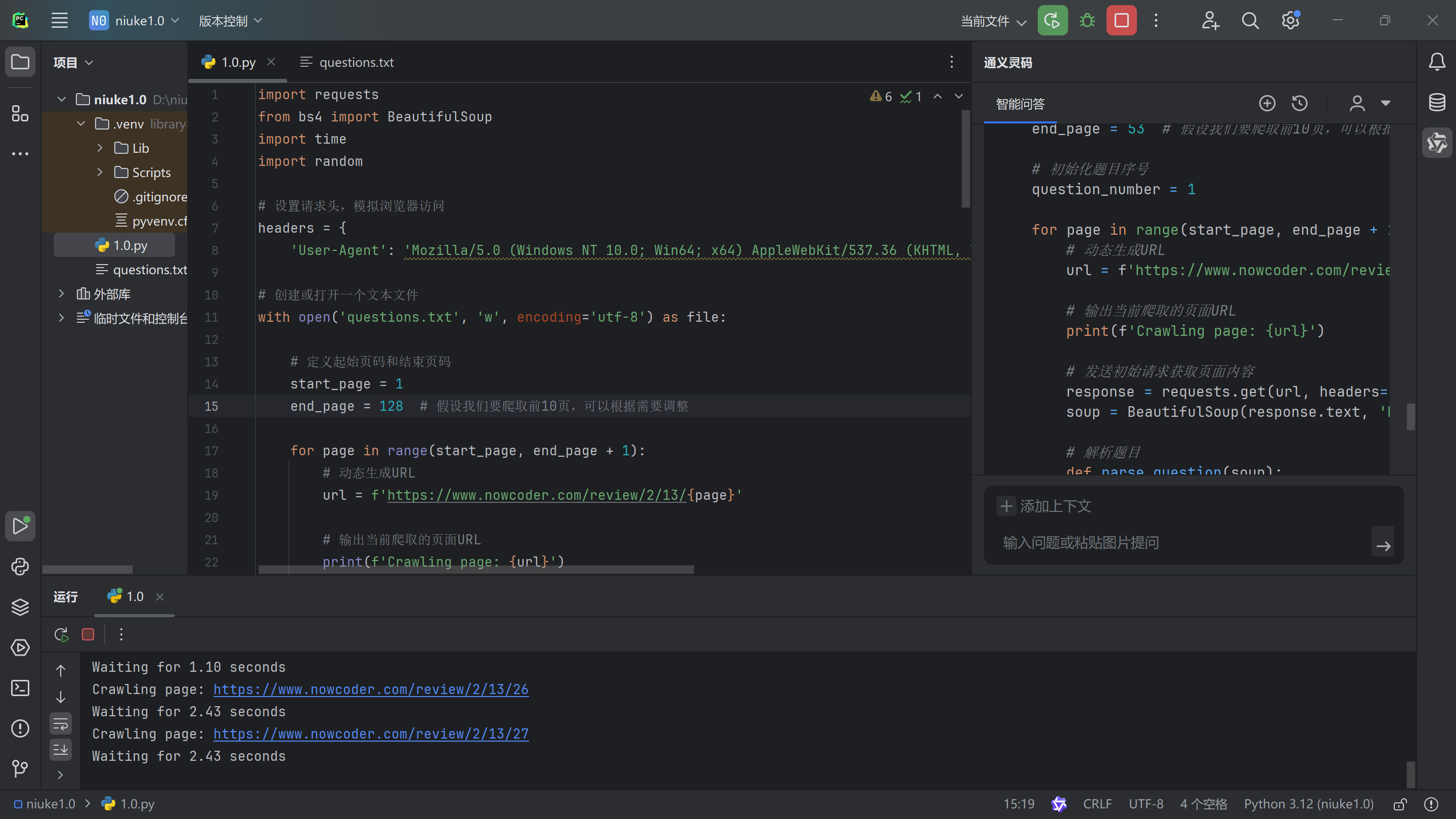
 牛客网题目爬取实验 文章描述 - 手动复制牛客网题目,实在太繁琐,因此决定使用爬虫去完成这些繁琐的工作,但问题来了,不会写代码,怎么办呢,身为21世纪,怎么能不用AI去写代码呢,于是有了今天的实验。 第一步选择软件,配置python环境 我这里选用的软件是pycharm,然后安装了通义灵码的插件,方便让AI帮我写代码 。🤫 m4oz8ckj.png图片 第二步查看题目的html代码 根据代码我们可以看到,题目和选项还有答案都在代码里面,我们要提取题目和选项还有答案要怎么做呢,难道要手动提取吗,怎么可能,前面的AI都安装好了,当然是让AI自己去处理了😉 <div class="final-box clearfix"> <div class="result-subject-item answer-primary-mod"> <div class="final-model-title clearfix"> <span class="final-order">1</span> <h2> <span>单选题</span> <span class="final-order-num"> <em class="final-green-words">1</em> /<span>128</span> </span> </h2> </div> <div class="final-question"> 一般用户更喜欢使用的系统是()。 </div> </div> <div class="result-subject-item answer-primary-mod"> <h1>参考答案</h1> <div class="result-answer-item "> 手工操作 </div> <div class="result-answer-item "> 单道批处理 </div> <div class="result-answer-item "> 多道批处理 </div> <div class="result-answer-item green-answer-item"> 多用户分时系统 </div> <div class="final-action clearfix"> <div class="final-function"> <a class="check-error" href="javascript:void(0);">纠错</a> <a class="link-collect click-follow nc-req-auth" href="javascript:void(0);"> 收藏 </a> </div> <div class="subject-next"> <a target="_blank" class="btn btn-primary" href="/questionTerminal/c0ebadeb49ff428788f396b2aeddc161">查看讨论</a> </div> </div> </div> </div>...m4ozr68u.png图片 开始给AI下达指令,成功爬取选择题 m4ozywbq.png图片 把题目的html代码发给AI,并告诉AI要做什么事情,然后AI就可以直接生成好爬取的代码了,当你以为这么快就结束的时候,那就错了,因为给AI的只是一个题的html代码,AI不能自己去浏览网页里面有什么,所以第一次的代码肯定运行结果是错的,那错了怎么办呢,当然还是找AI了😂 m4p03099.png图片 m4p04sau.png图片 m4p04xcf.png图片 m4p04z2e.png图片 m4p050s5.png图片 然后就经过一次一次又一次的尝试,终于控制台输出了我们想要的结果,题目和选项还有答案都爬取到了,那接下来就是让AI帮我们把爬取的内容换成我们想要的格式。 m4p0743o.png图片 m4p085ts.png图片 m4p088ss.png图片 终于再一次一次的命令下,AI不负众望完成了选择题的爬取! m4p09cfv.png图片 爬取判断题和问答题,没想到还要处理多选题 既然是题库,那肯定是有多种题目类型的,但是牛客网对题目的分类并不明确,因此我让AI去用代码进行题目的判断,判断题的规律就是只有对错两个选项,选择题只少会有四个选项,那么剩下的就是问答题了,所以我们让AI去用代码判断题目类型,然后按照不同题目类型的格式去保存,就这样爬虫实验取得圆满成功。 m4p0elwr.png图片 m4p0epi8.png图片 m4p0euk6.png图片 m4p0ew1r.png图片 AI最终生成的爬虫代码 import requests from bs4 import BeautifulSoup import time import random # 设置请求头,模拟浏览器访问 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'} # 创建或打开一个文本文件 with open('questions.txt', 'w', encoding='utf-8') as file: # 定义起始页码和结束页码 start_page = 1 end_page = 128 # 假设我们要爬取前10页,可以根据需要调整 for page in range(start_page, end_page + 1): # 动态生成URL url = f'https://www.nowcoder.com/review/2/13/{page}' # 输出当前爬取的页面URL print(f'Crawling page: {url}') # 发送初始请求获取页面内容 response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') # 解析题目 def parse_question(soup): question_div = soup.find('div', class_='final-question') if question_div: return question_div.text.strip() return None # 解析选项 def parse_options(soup): options = [] option_divs = soup.find_all('div', class_='result-answer-item') for div in option_divs: options.append(div.text.strip()) return options # 解析答案 def parse_answer(soup): answers = [] answer_divs = soup.find_all('div', class_='green-answer-item') for div in answer_divs: answers.append(div.text.strip()) return answers # 解析问答题答案 def parse_essay_answer(soup): essay_answer_div = soup.find('div', class_='design-answer-box') if essay_answer_div: return essay_answer_div.text.strip() return None # 解析题目、选项和答案 question = parse_question(soup) options = parse_options(soup) answers = parse_answer(soup) essay_answer = parse_essay_answer(soup) # 提取题目序号 question_number = int(url.split('/')[-1]) # 格式化输出并写入文件 if question: if len(options) == 2 and set(options) == {'对', '错'}: # 判断题 formatted_question = f"{question_number}. {question}\n" formatted_options = "▢对\n▢错\n" formatted_answer = f"答案:{''.join(answers)}\n\n" file.write(formatted_question + formatted_options + formatted_answer) elif options: # 选择题或多选题 formatted_question = f"{question_number}. {question}\n" formatted_options = "" correct_option_indices = [] for i, option in enumerate(options, start=65): # 65 对应 ASCII 的 'A' formatted_options += f"{chr(i)}. {option}\n" if any(answer in option for answer in answers): correct_option_indices.append(chr(i)) formatted_answer = f"答案:{''.join(correct_option_indices)}\n\n" file.write(formatted_question + formatted_options + formatted_answer) else: # 问答题 formatted_question = f"{question_number}. {question}\n" formatted_answer = f"答案:{essay_answer}\n\n" file.write(formatted_question + formatted_answer) # 等待一段时间,模拟人为操作 delay = random.uniform(1, 3) # 随机生成1到3秒之间的延时 print(f'Waiting for {delay:.2f} seconds') time.sleep(delay) ...
牛客网题目爬取实验 文章描述 - 手动复制牛客网题目,实在太繁琐,因此决定使用爬虫去完成这些繁琐的工作,但问题来了,不会写代码,怎么办呢,身为21世纪,怎么能不用AI去写代码呢,于是有了今天的实验。 第一步选择软件,配置python环境 我这里选用的软件是pycharm,然后安装了通义灵码的插件,方便让AI帮我写代码 。🤫 m4oz8ckj.png图片 第二步查看题目的html代码 根据代码我们可以看到,题目和选项还有答案都在代码里面,我们要提取题目和选项还有答案要怎么做呢,难道要手动提取吗,怎么可能,前面的AI都安装好了,当然是让AI自己去处理了😉 <div class="final-box clearfix"> <div class="result-subject-item answer-primary-mod"> <div class="final-model-title clearfix"> <span class="final-order">1</span> <h2> <span>单选题</span> <span class="final-order-num"> <em class="final-green-words">1</em> /<span>128</span> </span> </h2> </div> <div class="final-question"> 一般用户更喜欢使用的系统是()。 </div> </div> <div class="result-subject-item answer-primary-mod"> <h1>参考答案</h1> <div class="result-answer-item "> 手工操作 </div> <div class="result-answer-item "> 单道批处理 </div> <div class="result-answer-item "> 多道批处理 </div> <div class="result-answer-item green-answer-item"> 多用户分时系统 </div> <div class="final-action clearfix"> <div class="final-function"> <a class="check-error" href="javascript:void(0);">纠错</a> <a class="link-collect click-follow nc-req-auth" href="javascript:void(0);"> 收藏 </a> </div> <div class="subject-next"> <a target="_blank" class="btn btn-primary" href="/questionTerminal/c0ebadeb49ff428788f396b2aeddc161">查看讨论</a> </div> </div> </div> </div>...m4ozr68u.png图片 开始给AI下达指令,成功爬取选择题 m4ozywbq.png图片 把题目的html代码发给AI,并告诉AI要做什么事情,然后AI就可以直接生成好爬取的代码了,当你以为这么快就结束的时候,那就错了,因为给AI的只是一个题的html代码,AI不能自己去浏览网页里面有什么,所以第一次的代码肯定运行结果是错的,那错了怎么办呢,当然还是找AI了😂 m4p03099.png图片 m4p04sau.png图片 m4p04xcf.png图片 m4p04z2e.png图片 m4p050s5.png图片 然后就经过一次一次又一次的尝试,终于控制台输出了我们想要的结果,题目和选项还有答案都爬取到了,那接下来就是让AI帮我们把爬取的内容换成我们想要的格式。 m4p0743o.png图片 m4p085ts.png图片 m4p088ss.png图片 终于再一次一次的命令下,AI不负众望完成了选择题的爬取! m4p09cfv.png图片 爬取判断题和问答题,没想到还要处理多选题 既然是题库,那肯定是有多种题目类型的,但是牛客网对题目的分类并不明确,因此我让AI去用代码进行题目的判断,判断题的规律就是只有对错两个选项,选择题只少会有四个选项,那么剩下的就是问答题了,所以我们让AI去用代码判断题目类型,然后按照不同题目类型的格式去保存,就这样爬虫实验取得圆满成功。 m4p0elwr.png图片 m4p0epi8.png图片 m4p0euk6.png图片 m4p0ew1r.png图片 AI最终生成的爬虫代码 import requests from bs4 import BeautifulSoup import time import random # 设置请求头,模拟浏览器访问 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'} # 创建或打开一个文本文件 with open('questions.txt', 'w', encoding='utf-8') as file: # 定义起始页码和结束页码 start_page = 1 end_page = 128 # 假设我们要爬取前10页,可以根据需要调整 for page in range(start_page, end_page + 1): # 动态生成URL url = f'https://www.nowcoder.com/review/2/13/{page}' # 输出当前爬取的页面URL print(f'Crawling page: {url}') # 发送初始请求获取页面内容 response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, 'html.parser') # 解析题目 def parse_question(soup): question_div = soup.find('div', class_='final-question') if question_div: return question_div.text.strip() return None # 解析选项 def parse_options(soup): options = [] option_divs = soup.find_all('div', class_='result-answer-item') for div in option_divs: options.append(div.text.strip()) return options # 解析答案 def parse_answer(soup): answers = [] answer_divs = soup.find_all('div', class_='green-answer-item') for div in answer_divs: answers.append(div.text.strip()) return answers # 解析问答题答案 def parse_essay_answer(soup): essay_answer_div = soup.find('div', class_='design-answer-box') if essay_answer_div: return essay_answer_div.text.strip() return None # 解析题目、选项和答案 question = parse_question(soup) options = parse_options(soup) answers = parse_answer(soup) essay_answer = parse_essay_answer(soup) # 提取题目序号 question_number = int(url.split('/')[-1]) # 格式化输出并写入文件 if question: if len(options) == 2 and set(options) == {'对', '错'}: # 判断题 formatted_question = f"{question_number}. {question}\n" formatted_options = "▢对\n▢错\n" formatted_answer = f"答案:{''.join(answers)}\n\n" file.write(formatted_question + formatted_options + formatted_answer) elif options: # 选择题或多选题 formatted_question = f"{question_number}. {question}\n" formatted_options = "" correct_option_indices = [] for i, option in enumerate(options, start=65): # 65 对应 ASCII 的 'A' formatted_options += f"{chr(i)}. {option}\n" if any(answer in option for answer in answers): correct_option_indices.append(chr(i)) formatted_answer = f"答案:{''.join(correct_option_indices)}\n\n" file.write(formatted_question + formatted_options + formatted_answer) else: # 问答题 formatted_question = f"{question_number}. {question}\n" formatted_answer = f"答案:{essay_answer}\n\n" file.write(formatted_question + formatted_answer) # 等待一段时间,模拟人为操作 delay = random.uniform(1, 3) # 随机生成1到3秒之间的延时 print(f'Waiting for {delay:.2f} seconds') time.sleep(delay) ...